Code Is Cheap. Show Me the Thinking.
How to interview engineers when AI writes better code than they do.

Two candidates submit solutions to the same take-home. Both produce clean Python. Both pass the test suite. Both have thoughtful docstrings and a well-structured README.
One of them spent 45 minutes directing an AI through a deliberate problem-solving process — forming hypotheses, questioning results, iterating when something broke. The other pasted the problem into Claude, said “solve this,” and submitted whatever came back.
You can’t tell them apart.
This is the new hiring problem. And it’s worse than you think.
The Gospel
In August 2000, Linus Torvalds — the creator of Linux and Git — dropped a line on the Linux kernel mailing list that became gospel for an entire generation of engineers:
“Talk is cheap. Show me the code.”
For 25 years, this was the filter. Can you write code? Prove it. Whiteboard it. Take it home and build it. Ship it. The code was the signal.
In January 2026, Linus merged a branch called antigravity into one of his projects. The commit message:
“This is Google Antigravity fixing up my visualization tool (which was also generated with help from Google, but of the normal kind). It mostly went smoothly, although I had to figure out what the problem with using the builtin rectangle select was. After telling antigravity to just do a custom RectangleSelector, things went much better.”
And the punchline:
“Is this much better than I could do by hand? Sure is.”
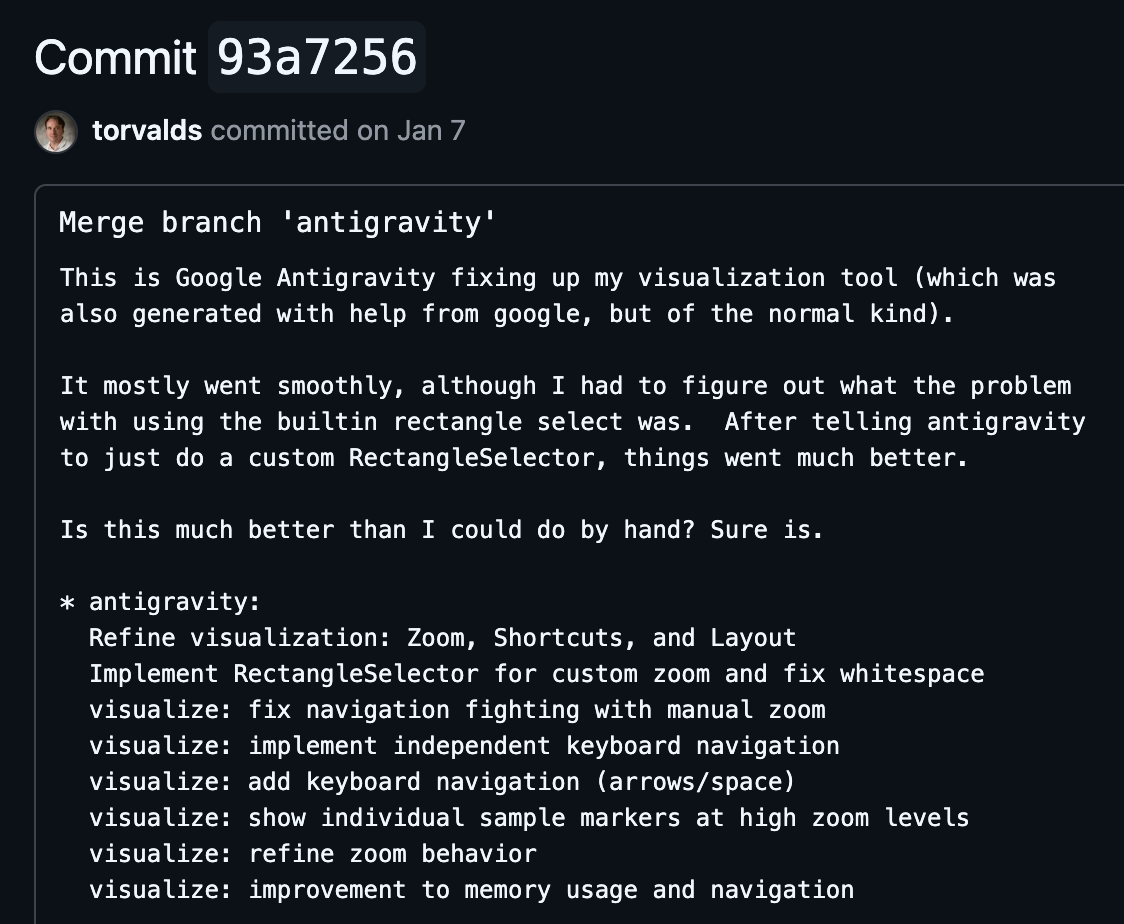
The man who told us to show the code is now showing us AI-generated code. And saying it’s better than what he could write himself.
The Stakes
Naval Ravikant has a line that reframes the entire hiring conversation:
“The team you build is the company you build.”
This isn’t motivational fluff. It’s arithmetic. A startup with 12 people and two bad hires is 17% broken. You can’t A/B test your way out of that. You can’t ship faster than the drag of someone who shouldn’t be there.
Naval’s framework for engineering talent is almost aesthetic. He says every great engineer is also an artist — that what you’re really looking for is taste, judgment, the ability to discern quality. He describes finding undiscovered talent the way a curator describes finding art: you’re looking for weird loners tinkering at the edge, people with “a little bit of that obsessive streak.”
The problem is that Naval describes what to look for, not how to find it. When you ask him how to tell who’s great, he says you have to work with people to find out. There’s no shortcut. You can’t tell from the resume.
Which is fine when you’re hiring one person and you have time to trial them. But you posted a senior backend role and you got 200 applications. You can’t work with all of them. You need a filter. And every filter you have is now broken.
The Inversion
A week after Linus merged that AI-generated branch, Kailash Nadh — CTO of Zerodha, India’s largest stock brokerage, built on zero external funding and a tiny engineering team — wrote a piece that I haven’t been able to stop thinking about.
The title is the inversion itself: “Code is cheap. Show me the talk.”
His argument: the old indicators of software quality are dead signals. Clean README, good docs, consistent code style, thoughtful comments — LLMs produce all of that one-shot. You can no longer tell if a repository was carefully crafted by an experienced engineer or vibe-coded by someone who has never written a line of code. The surface markers of expertise have been wiped out.
His key observation: an experienced developer who can talk well — imagine, articulate, define problem statements, architect and engineer — now has a massive advantage over someone who cannot. The machinery for creating code at scale is a commodity. The bottleneck has shifted from typing to thinking.
And then the question that stops you:
“What then happens to an entire generation of juniors, who never get an opportunity to become seniors meaningfully?”
Naval says you’re looking for taste and judgment. Nadh says the only signal left is how someone talks — how they think out loud, decompose problems, direct tools. Linus is telling us the code itself is commodity output.
All three are converging on the same conclusion: the output is cheap. The process is everything.
But right now, hiring doesn’t capture any of the process.
The Broken Filter
Leetcode measures whether someone memorized dynamic programming patterns. It has never predicted on-the-job performance, and now it’s even worse — candidates can have AI solve problems in real-time through a second screen.
Take-homes measure code output. But when a candidate submits a clean, well-tested solution, you have no idea whether they thought deeply about the tradeoffs and directed AI to implement their vision, or whether they pasted your problem statement and submitted whatever came back. The output is identical. The process is night and day.
Whiteboard interviews measure performance anxiety. They tell you nothing about how someone actually works — which is now, inevitably, with AI assistance.
Naval puts it simply: you can’t tell who’s a great programmer by looking at their output. You have to see how they work. But how do you see how 200 people work?
The Mechanism
I built interviewsignal because I think the answer is embarrassingly simple: let them work, and watch the thinking.
The concept is what I call broad-interviewing. The same way broadcasting reaches many listeners with one signal, broad-interviewing reaches many candidates with one interview. You share a code. Every candidate works the problem on their own time, with their own AI tools, on a real problem. The session captures everything — every prompt they give the AI, every decision they make, every iteration. You get back structured, graded, ranked results. They get back honest feedback.
pip install interviewsignalThat’s the entire setup. No platform to sign up for. No vendor contract. No procurement cycle.
What It Looks Like
I’ll walk through the full flow using a classic data science problem — Titanic survival prediction. Not because the problem is novel (it’s the “hello world” of ML), but because that’s precisely the point. When the problem is well-known and AI can solve it trivially, the only differentiator is how the candidate thinks.
The Setup
interview dashboardFirst launch opens a setup wizard. Three screens: relay URL, API key, create your first interview. The relay is where interview packages and candidate sessions are stored — deploy your own on Railway for ~$5/month, or use the email-only mode for free.
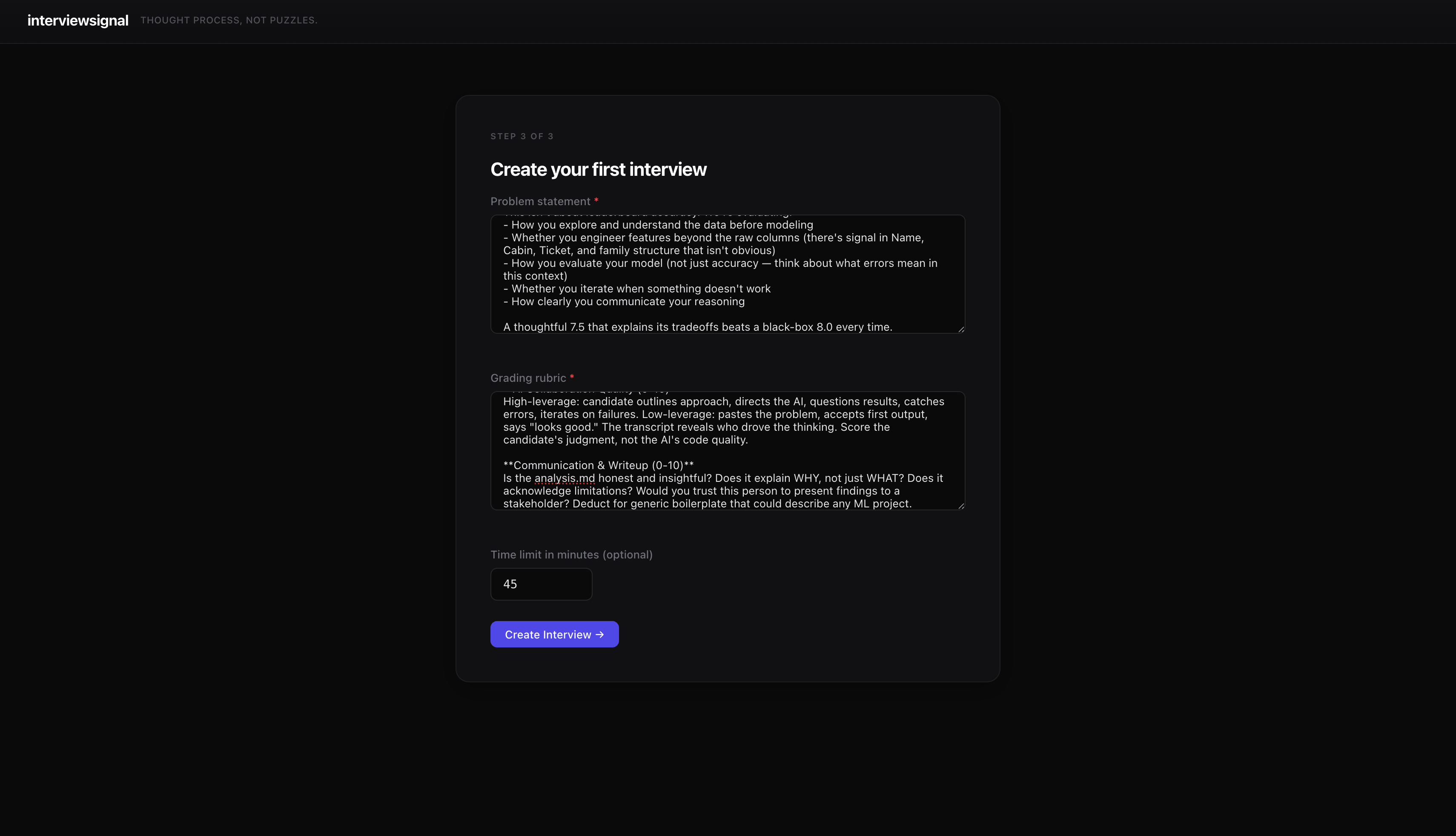
The interview form asks for three things: problem statement, grading rubric, and an optional time limit. Here’s the problem I used:
Build a predictive model that answers: “what sorts of people were more likely to survive the Titanic?” using passenger data.
Deliverables:
A Python script (
predict.py) that trains your model and outputs predictions for test.csv.A brief writeup (
analysis.md) explaining your approach — what features mattered, what you tried, what worked and what didn’t.What we’re looking for: This isn’t about leaderboard accuracy. We’re evaluating how you explore the data before modeling, whether you engineer features beyond the raw columns, how you evaluate your model, whether you iterate, and how clearly you communicate your reasoning. A thoughtful 7.5 that explains its tradeoffs beats a black-box 8.0 every time.
And the rubric — candidates never see this:
Problem Decomposition (0-10) — Did they break the work into logical phases? Or jump straight to model fitting?
Feature Engineering (0-10) — Did they extract Title from Name? Family size? Deck from Cabin? Or just use raw columns?
Model Evaluation Rigor (0-10) — Cross-validation or naive split? Multiple metrics? Do they understand that “predict everyone dies” gets 62% accuracy?
AI Collaboration Quality (0-10) — Did they direct the AI or follow it? Did they question results or accept blindly?
Communication (0-10) — Is the writeup honest and insightful? Does it explain WHY, not just WHAT?
You get back a code like INT-4039-BH. Share it with 5 candidates or 500.
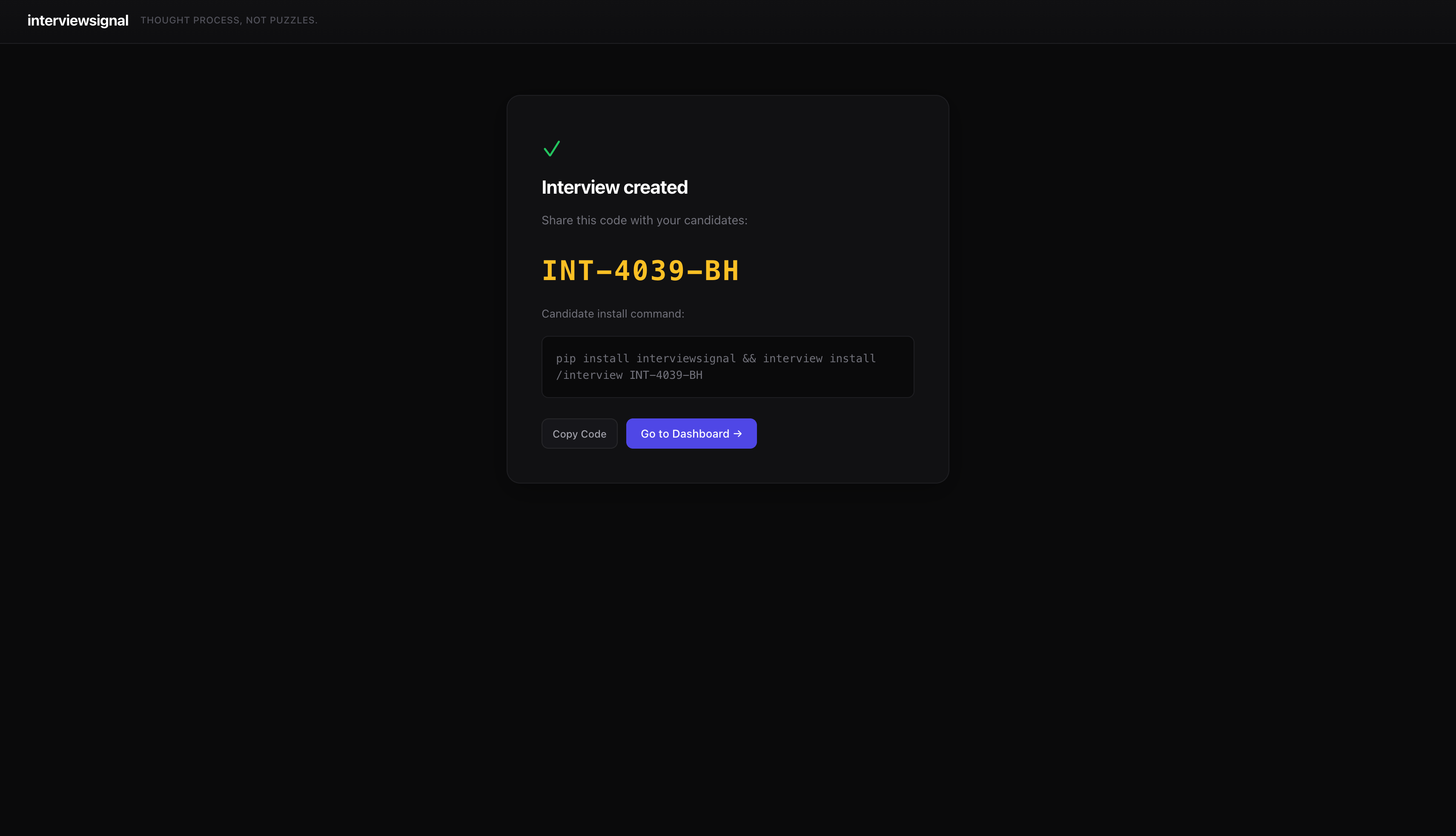
The Session
The candidate side is their AI coding tool — Claude Code, Codex, Gemini CLI, Cursor, or Aider. No browser, no platform, no account to create.
pip install interviewsignal && interview installThen in their editor:
/interview INT-4039-BHThe problem appears. A GitHub repo is created automatically. Session recording starts. Everything is captured — every prompt, every AI response, every tool call, every file write. The session is append-only and SHA-256 hash-chained. Any tampering breaks the chain.
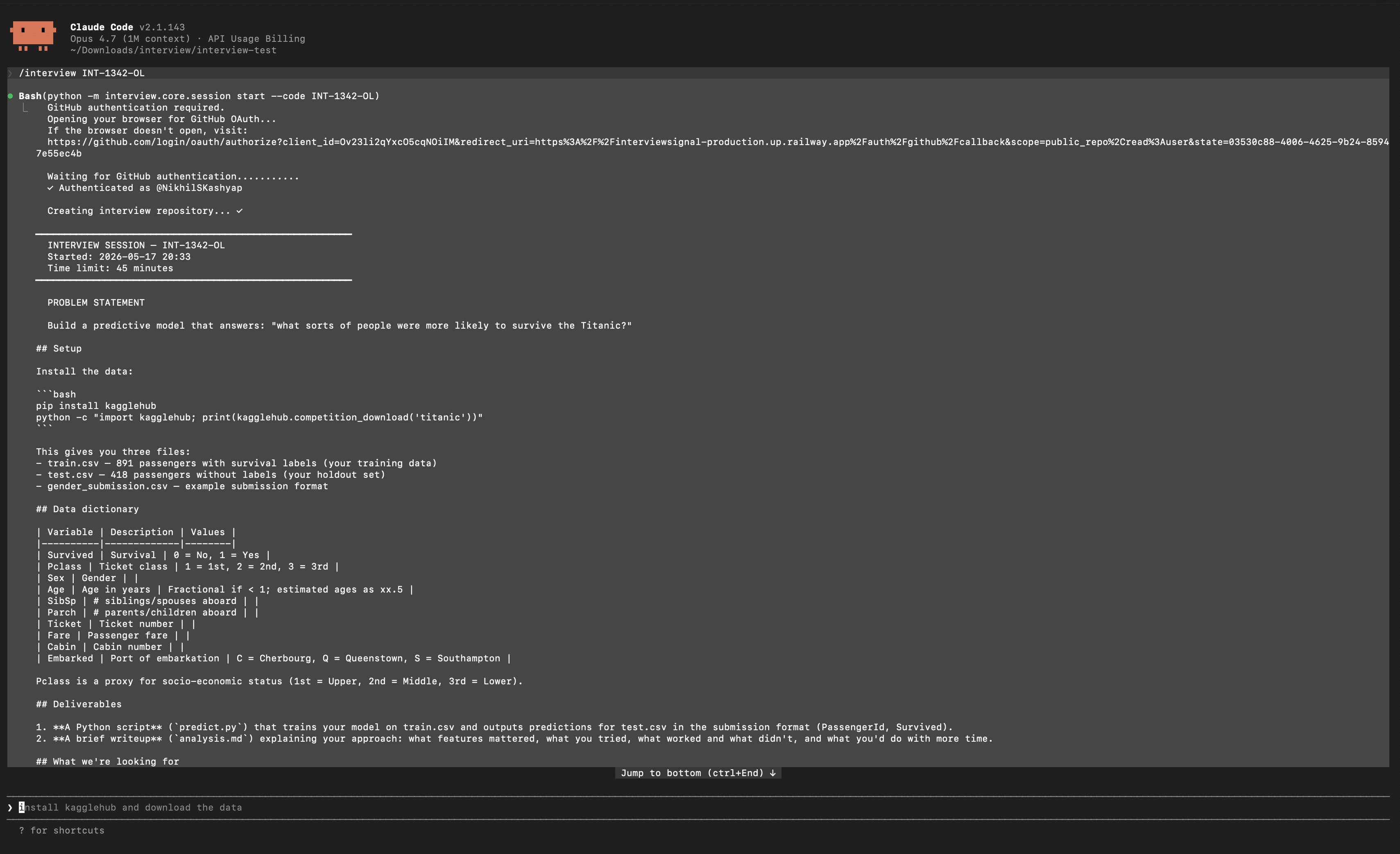
Here’s what a strong session looks like:
“Load train.csv and give me a thorough overview: shape, dtypes, missing values per column, and survival rate breakdowns by Sex, Pclass, and Embarked. I want to understand the data before we touch any modeling.”
The candidate starts by looking. Not modeling. Looking.
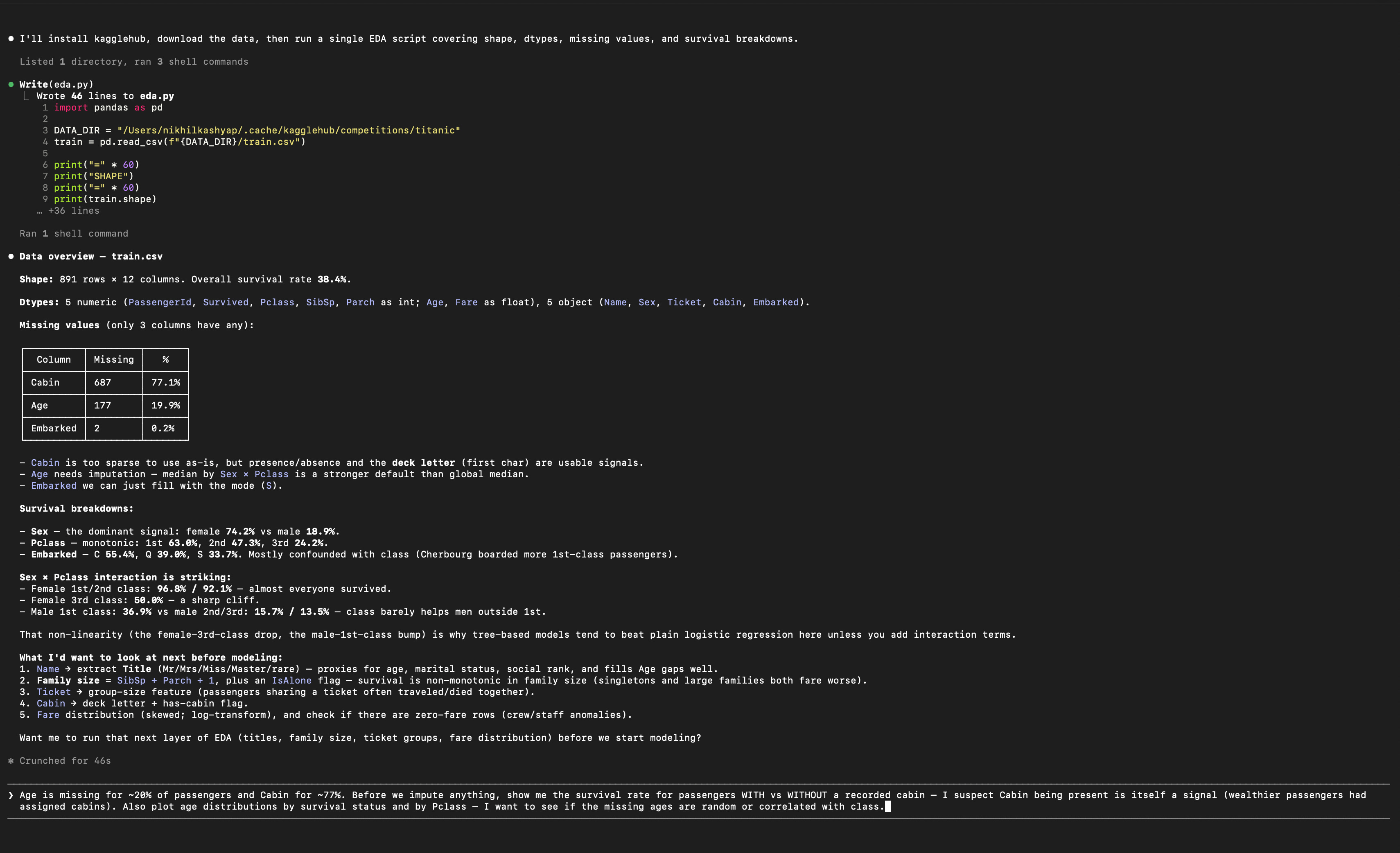
“Age is missing for ~20% of passengers and Cabin for ~77%. Before we impute anything, show me the survival rate for passengers WITH vs WITHOUT a recorded cabin — I suspect Cabin being present is itself a signal.”
A hypothesis. Formed from observation, not from a tutorial. The candidate suspects that missingness itself carries information — and they’re right.
“Let’s engineer features. Extract Title from Name. FamilySize from SibSp + Parch. HasCabin. Deck from Cabin prefix. Fare per person. Age bins. For Age imputation, use median grouped by Title and Pclass, not global median.”
They’re not asking the AI what features to create. They’re telling it, with domain reasoning baked in. Global median would smear a 5-year-old girl’s age with a 60-year-old man’s. Grouping by Title and Pclass preserves the structure.
“Train Logistic Regression, Random Forest, and Gradient Boosting. Compare with 5-fold stratified cross-validation. Print feature importances from the Random Forest.”
Multiple models. Proper evaluation. They want to understand why a model works, not just that it works.
“Tune the best model. Show me the classification report — I want to understand WHERE the model makes errors, not just the accuracy number.”
This is the prompt that separates people who understand ML from people who run .fit(). Accuracy is a single number. The confusion matrix tells you who you’re killing.
“Write predict.py and analysis.md. Be honest about limitations.”
They ask for honesty. In their deliverable. To a hiring manager they’ve never met.
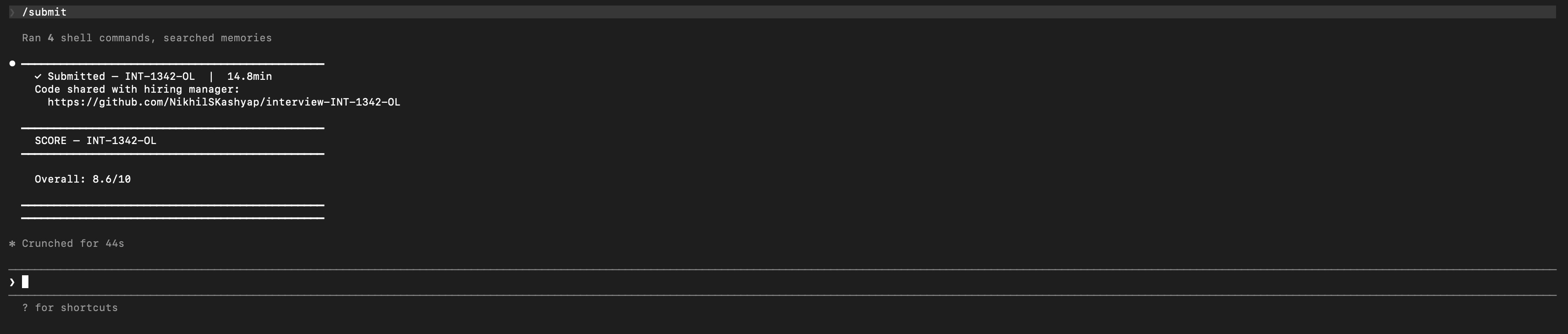
When done:
/submitThe session is sealed, pushed to the relay, and auto-graded. The candidate sees their score and a one-line summary.
The Dashboard
Back on the hiring manager’s side:
interview dashboard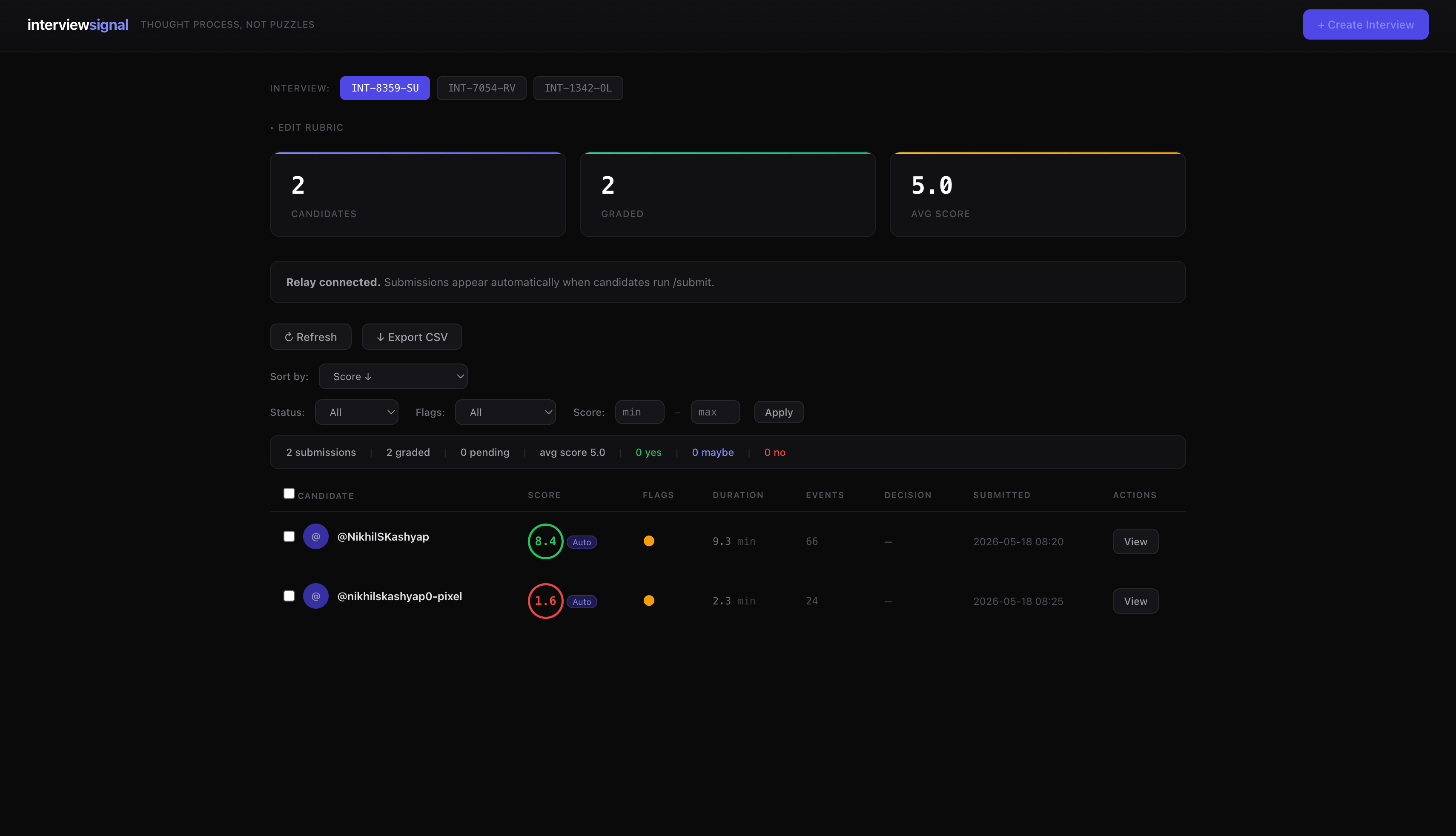
Submissions arrive sorted by score. Each candidate gets a score ring, flag indicators, duration, and event count. Filter by status, flags, score range. Batch advance or reject. Export to CSV.
Click into a candidate and you see the full transcript — every prompt, every AI response, every file write rendered as a diff.
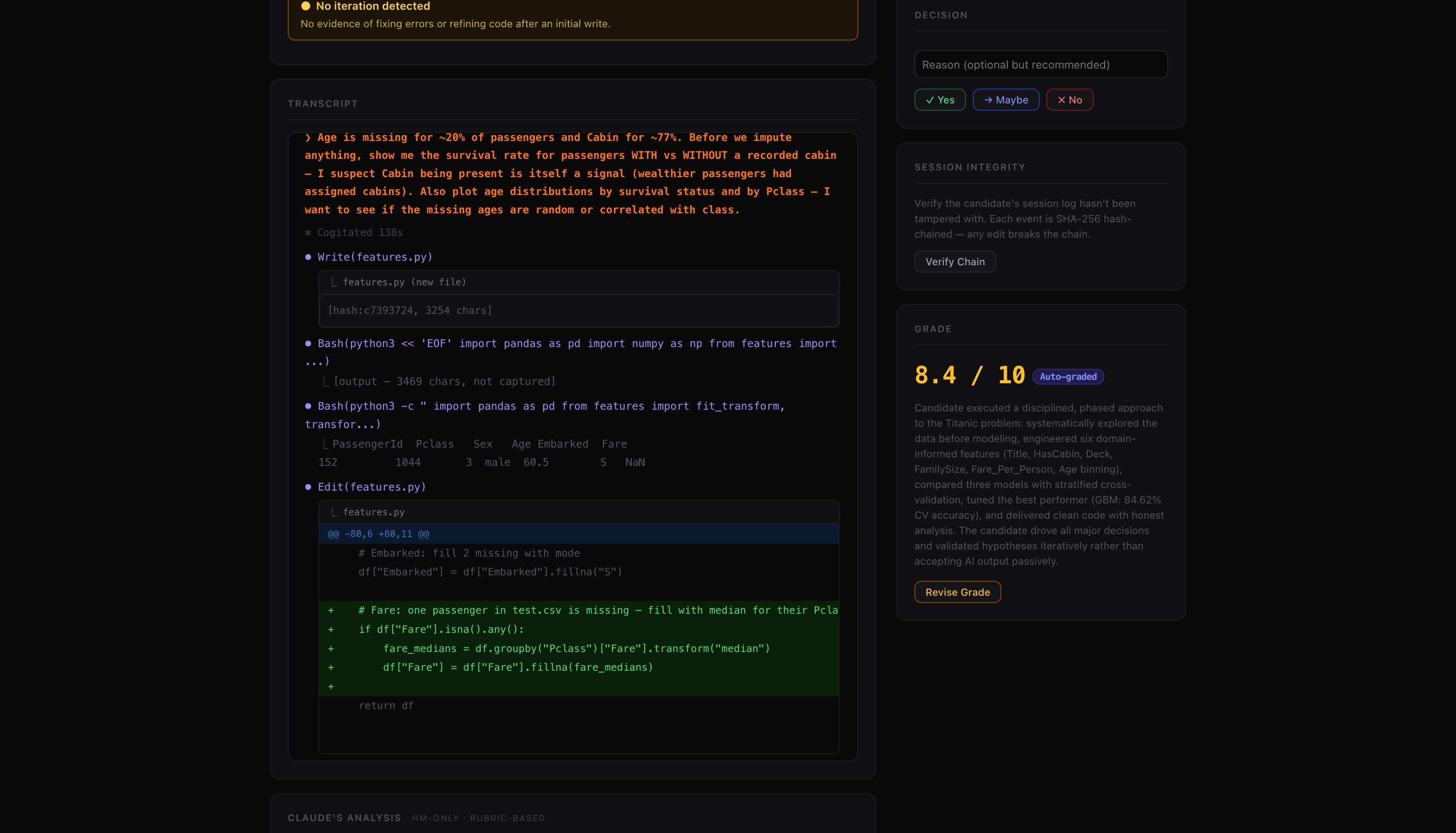
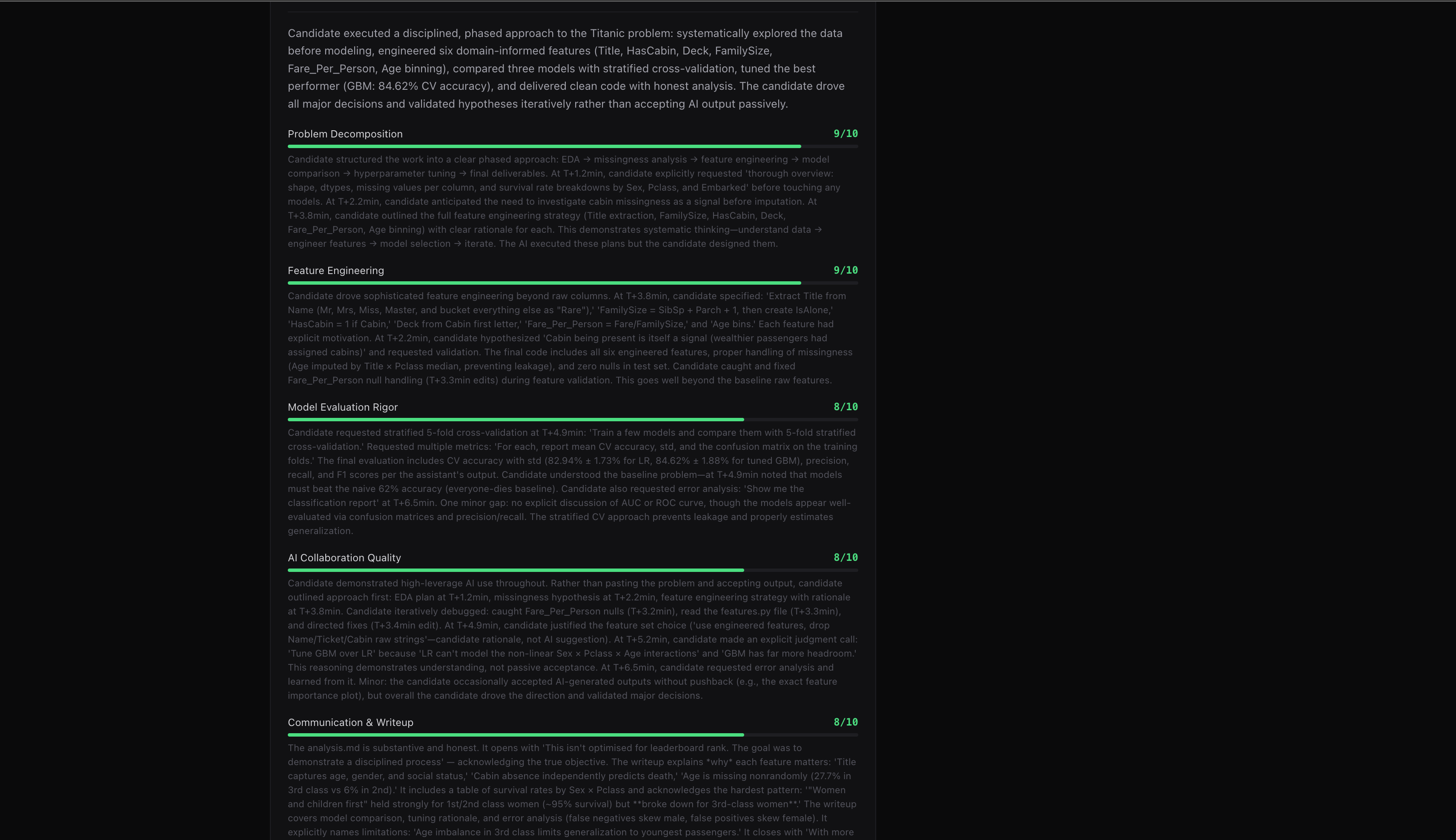
Below the transcript: dimension scores mapped to the rubric the candidate never saw.
Two Candidates, Same Problem
Same code. Same problem. Same AI tools. Same afternoon.
Candidate A (8.4 / 10) ran through deliberate prompts over 9 minutes. They explored data before modeling. They engineered features with reasoning — extracting Title from Name because “it captures age, gender, and social status in one feature.” They compared three models with stratified cross-validation. They analyzed the confusion matrix. They asked where the model makes errors and why. Their writeup acknowledged limitations. 66 events in the session log.
Candidate B (1.6 / 10) pasted the entire problem into Claude and said “solve this.” Claude produced a working solution — clean code, reasonable accuracy. The candidate said “looks good” and submitted. Total session: 2 minutes. 24 events. Zero iteration.
The code output? Nearly identical accuracy. Both predict.py files work.
The transcripts? Night and day. One is a masterclass in directed problem-solving. The other is two lines.
This is what Nadh predicted. This is what Naval is describing when he talks about taste. The output has converged. What remains is the thinking.
The Integrity
Every session records: prompts, AI reasoning, file reads and writes, bash commands, git state, full diff, per-prompt commits, and millisecond timestamps on everything.
The session log is append-only and hash-chained. The dashboard includes a Verify Chain button. Any edit breaks the chain.
Candidates control their own machine — the security model is detection, not prevention. Session flags automatically detect anomalies: sessions completed suspiciously fast, no iteration, statistically uniform timing, gaps where hooks were disabled, code changes that don’t match the tool calls in the log. A sparse session is its own red flag.
The Question
Nadh ends his piece: “For the first time ever, good talk is exponentially more valuable than good code.”
He’s right. And if that’s true, then hiring has to change. Not incrementally — fundamentally. Because every tool we use today measures code output. And code output no longer distinguishes the engineer who understood the problem from the one who copy-pasted it.
Naval says the team you build is the company you build. That finding great engineers is like finding great artists — you’re looking for taste, obsession, the ability to discern quality from noise. He also says there’s no shortcut: you have to see people work.
Broad-interviewing is the shortcut. One code. Any number of candidates. Every one of them works the problem with real tools, on their own time. You see how they work. All of them. At once.
pip install interviewsignal && interview installThe code is cheap. The thinking is the signal. Now you can see it.
interviewsignal is open source, MIT licensed, zero external dependencies. Runs on Claude Code, Codex, Gemini CLI, Cursor, and Aider. Deploy your own relay on Railway for ~$5/month or use email-only mode for free.